The Ascent of AI: Standing on the Shoulders of Data Management Giants
In the seventeenth century the great English scientist Sir Isaac Newton radically changed our understanding of the Universe...


July 2025, Nigel Turner, Principal Consultant, EMEA
In the seventeenth century the great English scientist Sir Isaac Newton radically changed our understanding of the Universe. Amongst his many achievements he discovered the laws of motion, the law of gravity and the composition of light. His model of the cosmos became accepted scientific truth for over 300 years, only fundamentally challenged by Einstein’s theories of relativity at the start of the twentieth century.
Newton was once asked how he had managed to produce such groundbreaking discoveries. His modest reply was “If I have seen further than others, it is by standing on the shoulders of giants”. In saying this, Newton was acknowledging that his insights were rooted in the legacy left by other scientists who had gone before him, and he could not have achieved what he did without the foundations they put in place.
Today a lot of faith (and time & money) is being put into Artificial Intelligence (AI) to unlock many key insights into our contemporary world. AI champions claim the application of AI will transform businesses, indicate new ways of solving problems, improve the customer experience, accelerate decision making and so on. The list of potential benefits is often seen as limitless, which goes a long way to explain why AI investment is expected to skyrocket to around $968 billion globally by 2032. [1]
There is no doubt that AI is truly an innovative and disruptive technology and so many of these promised benefits will no doubt accrue. But to deliver the expected step change of AI, those who advocate and practise it will also need to embrace the fact that its roots and success lie in the disciplines of data management. Like Newton, AI will stand (or fall) on the shoulders of the giants of more traditional data management disciplines that will be needed to underpin it.
There is growing evidence, however, that in the frantic race to adopt AI, many organisations are already losing sight of this and are trying to implement AI without a due focus on data management. For example, in a recent paper Gartner predicts that 30% of generative AI (GenAI) projects will fail in 2025.[2] The primary cause of failure will be poor data quality, exacerbated by inadequate control of risk, uncontrolled costs, and unclear business value. It is self-evident that AI can only be as good as the data that it is trained on and analyses, but it appears as if things will go wrong before lessons are learned. As has sadly often been the case in the history of IT technologies, the realisation that data quality is an essential prerequisite of success will be tackled reactively and not proactively by many trying to apply AI. But at least there is good news. AI will put a renewed and more urgent emphasis on the importance of having complete, trusted and accurate data, never a bad thing, not just for AI but to enhance business efficiency generally.
It’s not only data quality that is key to successful AI. All other data management capabilities also have a vital role to play. The Data Management Association’s (DAMA) Data Management Book of Knowledge (DMBOK) Version 2 [3] breaks down data management into eleven primary disciplines.
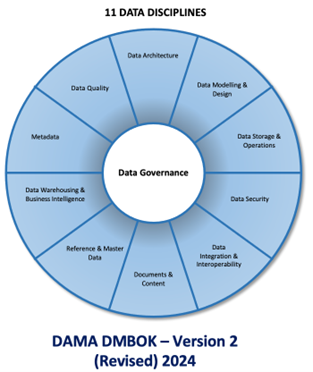
All these disciplines are AI enablers and so have an important role to play in AI success or failure. These disciplines, and how they support AI, are:
What this all demonstrates is that implementing AI and deriving its expected value, particularly on a large scale, depends upon an organisation having the right data management foundations, encompassing all the above disciplines. Shortcomings in any will have an adverse, and potentially fatal, impact on the success of any AI project. At the organisation level, therefore, developing a data strategy, usually encompassing all the DMBOK disciplines, is a prime requirement and reference point for any AI strategy. Needless to say, the two strategies need to be developed in unison, with each absorbing and meeting the key requirements of the other.
At a delivery level this does not mean that AI should only be introduced when all these data capabilities are deemed fit for purpose. Most organisations are building their AI capabilities on a use case basis by finding real business problems to solve or opportunities to exploit and developing pilot and operational AI projects to tackle them. The important thing is that each of these use case projects assess and evaluate the data management capabilities required as the foundation of the use case and develop them accordingly. For example, if a use case focuses on gaining new insights into customer behaviour it needs to consider things such as current customer data quality, data governance with policies and controls to specify how customer data should be processed, that appropriate data models exist, APIs are in place that can connect key customer data sources and so on. By preparing the data foundations for any AI use case in this way, the organisation as a whole evolves its overall data capabilities.
Moreover, many of the data disciplines can themselves benefit from the introduction of AI. AI is already being used to enhance data quality management through automated error discovery and correction, and AI-enabled data catalogs are generating better metadata. Use of AI in Master Data Management solutions is now common, reducing manual effort by automating data quality, data security etc. So, the relationship between AI and data management disciplines is potentially of mutual benefit to both.
Although AI is not a data management discipline as such, it is closely interlinked with the data disciplines. AI is reliant on well-managed, accurate and trustworthy data, both to train its models and in operations to derive its insights and business benefits. If AI is to deliver its new era of innovation and change, just like Isaac Newton it must stand on the shoulders of the giants that precede it. If it doesn’t things can, and probably will, all too often go badly wrong.
[1] Cited in Informatica eBook, ‘AI Playbook for IT Leaders’ page 4.
[2] Gartner white paper “AI-Ready Data Essentials” page 2.
[3] DAMA – Data Management Book of Knowledge (DMBOK), Revised Second Edition, 2024




