
Data catalogues were, for years, engineered as read-only repositories, positioned as data dictionaries that crawled databases, ingested schemas, and presented a static snapshot of the data landscape. In this legacy model, metadata collection was a one-way street where data flowed into the catalogue, and human users read it to gain context.
However, as enterprise data ecosystems have expanded in volume and velocity, this passive approach has broken down. Modern data architectures require data catalogues to transition from their previously passive, read-only inventories into the read-write execution engines they’re heading towards today.
The Evolution of Metadata Ingress
To understand why a read-write architecture is necessary, it’s useful to look at how the role of metadata has evolved. Historically, metadata management was divided into distinct eras:
- The Manual Era (Pre-2000s): Catalogues were literal spreadsheets or basic data dictionaries documenting location and basic definitions.
- The Crawler Era (2000s–2015): Catalogues evolved to automatically pull technical metadata directly from database management systems to aid self-service analytics and governance.
- The Active Era (Post-2015): The rise of decentralised infrastructure, such as data mesh architectures and cloud data warehouses, necessitated automated, intelligent metadata extraction to handle the sheer variety of operational and governance signals.
These days, if a data catalogue cannot write back to the ecosystem, it remains a bottleneck. Experienced practitioners are shifting toward a closed-loop metadata architecture where the catalogue actively alters the state of downstream systems based on the metadata it processes.
The read-write catalogue
A read-write data catalogue observes and orchestrates metadata. This requires a transition from batch-based crawling to an event-driven, bidirectional framework. Instead of executing resource-intensive nightly scans, the catalogue integrates directly with enterprise event streams. Whenever a pipeline runs, a schema changes, or an observability tool logs a data quality failure, a live metadata event is published and immediately captured by the catalogue.
The true benefits are seen when the catalogue processes these incoming signals and executes downstream actions dynamically. The catalogue operates as an active supervisor rather than a passive observer. For instance:
- When descriptive or operational metadata flags that a dataset contains sensitive information, the catalogue writes back to the storage layer, instantly triggering access control adjustments or data masking policies.
- If operational metadata detects an upstream schema variation or data quality violation, the catalogue automatically instructs the coordination layer to pause downstream ingestion pipelines before corrupted data reaches executive dashboards.
Transitioning from relational tables to knowledge graphs
As data catalogues become more active, data architects face an infrastructure decision surrounding the know-how of modelling and storing the underlying metadata. Historically, enterprise catalogues relied on relational database management systems (RDBMS) to organise data inventories. This table-centric model, while highly structured and secure, is increasingly unsuited to the interconnectedness of modern data ecosystems. To achieve true active metadata orchestration, especially when mapping deep, column-level lineage and multi-layered data dependencies, advanced catalogues are migrating toward knowledge graphs.
Relational databases operate on predefined schemas. Data must fit cleanly into pre-determined boxes consisting of fixed tables, rows, and rigid primary-to-foreign key relationships. While this architecture is exceptionally well-suited for traditional transactional processing, it creates friction when applied to enterprise-wide metadata management for the following reasons:
- In a modern stack, new data tools, transformation layers, and analytical platforms are introduced constantly. Modifying a relational cataloguing schema to accommodate a brand-new type of metadata asset requires complex structural changes, database migrations, and careful consideration of downstream impacts.
- Mapping data lineage across an enterprise requires connecting disparate data points, from ingestion pipelines and cloud warehouses to business intelligence dashboards. In a relational database, querying these multi-layered relationships requires executing increasingly complex, nested SQL joins. As the number of monitored tables grows, query execution times slow down significantly, making real-time metadata analysis computationally prohibitive.
Knowledge graphs, on the other hand, depart from table-centric structures by representing metadata as a network of interconnected entities (nodes) and explicit relationships (edges or triplestores). This shift alters how a data catalogue scales and adapts.
Because knowledge graphs do not restrict data to rigid tabular structures, they offer great flexibility when expanding the metadata model. If a data engineering team introduces a new semantic layer or an AI training workflow, the catalogue can absorb these new entities and define fresh relationships on the fly. This extension occurs seamlessly, without the need to redesign an underlying database schema or risk disrupting existing documentation.
What’s more, the ultimate advantage of a knowledge graph backend within a data catalogue lies in its alignment with complex analytical processing and automated reasoning. Tracking data lineage is inherently recursive, and so traditional SQL struggle with native recursion, frequently requiring stored procedures that are difficult to maintain.
Knowledge graphs excel at multi-level traversals. During an infrastructure update, a data engineer can perform instantaneous impact analysis, mapping out complex dependencies and identifying downstream risks in a fraction of the time a relational database would require.
Unified coexistence
Choosing a knowledge graph engine does not mean abandoning the relational model entirely. In practice, data organisations frequently combine both approaches.
An enterprise might leverage a stable relational database to securely store core, granular metrics and individual data assets as key values with unique identifiers. Simultaneously, they implement a knowledge graph as an overarching analytical layer. This hybrid architecture pairs the structured precision of relational storage with the deep connectivity and cognitive alignment of a graph, delivering a data catalogue that is scalable and highly intuitive to traverse.
Active blueprints in production
To appreciate the value of a read-write data catalogue, it must be examined how active metadata operates in production. This is best explained in the following categories:
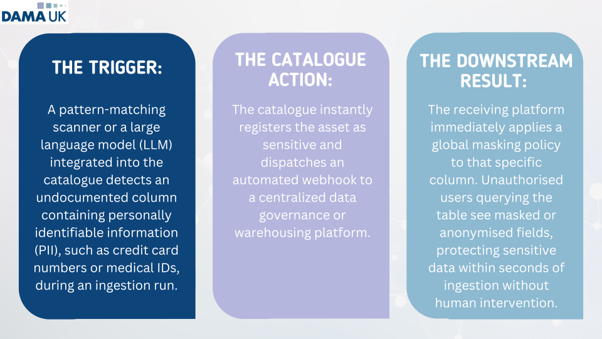
Dynamic access control (the security use case)
In a traditional setup, securing data requires data governance teams to manually review schemas and apply role-based access control (RBAC). This approach is slow and prone to human error. An active catalogue replaces this manual intervention with event-driven data protection.

Automated pipeline throttling (the quality use case)
Data quality issues frequently go unnoticed until an executive spots a broken metric on a critical dashboard. Active metadata allows the infrastructure to isolate data quality issues before they affect business decisions.
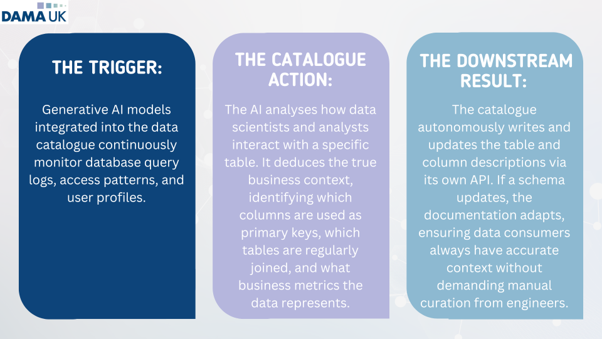
Self-healing documentation (the knowledge use case)
Data documentation is notoriously difficult to maintain; data dictionaries are often out of date the moment they are written. Active catalogues utilise user behaviour and operational context to document themselves.
Architectural bottlenecks
Transitioning to an active, read-write metadata architecture is the next step for mature data organisations. However, moving away from passive cataloguing introduces engineering hurdles that practitioners must work through.
API standardisation
The foundational mechanism of any active catalogue is its ability to trigger downstream actions across a fragmented data stack. This operations-heavy approach relies entirely on application programming interfaces (APIs) to transport metadata requests and execute instructions between systems.
However, as observed across the broader field of technology right now, APIs are only effective when governed by effective standards and protocols. Unfortunately, the modern data ecosystem currently lacks a level of universal harmony in terms of standardisation. Data tools often communicate using a mismatched array of private or partner APIs, switching inconsistently between different architectural approaches.
Without strict API standardisation, connecting a data catalogue to various orchestrators, security platforms, and warehouses becomes highly inefficient. Attempting to build an automated governance loop with non-standardised APIs is akin to building a complex structure out of mismatched materials. It would likely require extensive custom engineering, introduce security vulnerabilities, and degrade system reliability.
The risk of cascading failures and metadata loops
Beyond integration friction, introducing write capabilities into a data catalogue creates the risk of cascading operational failures. When a catalogue automatically alters the state of downstream infrastructure based on incoming metadata signals, it introduces the potential for infinite feedback loops.
For example, an automated data observability check might log a temporary freshness delay on a table, prompting the catalogue to write an instruction that pauses an ingestion pipeline. If that pipeline suspension inadvertently triggers a secondary metadata alert, the system can become trapped in an automated loop, locking out user access or wasting compute resources. To prevent these scenarios, practitioners must engineer strict state-management guardrails and establish circuit breakers within the metadata orchestration layer.
The future is active
The data catalogue is not just a passive inventory or an administrative task for compliance teams anymore. The demands of decentralised architectures and real-time analytics have forced quite a shift in how metadata is managed.
Moving to an active paradigm requires moving beyond the constraints of relational tables and embracing the fluid, interconnected intelligence of knowledge graphs. While the hurdles of API standardisation and loop management require careful engineering discipline, the rewards are undeniable. By repositioning the data catalogue into something that is automated and event-driven, data practitioners work towards turning static documentation into self-healing data intelligence.
Sources:
https://www.alation.com/blog/what-is-a-data-catalog/
https://www.ibm.com/docs/en/adffz/dbb/3.0.x?topic=samples-metadata-lifecycle
https://www.legislate.ai/blog/knowledge-graphs-vs-relational-databases
https://datawalk.com/relational-model-database-vs-the-datawalk-knowledge-graph/
https://www.finextra.com/the-long-read/1463/what-is-api-standardisation

